Architecting a Real-Time AI Assistant (J.A.R.V.I.S.) with the Gemini API and Concurrency in Rust
This is a walkthrough of my attempt at building a realtime assistant (J.A.R.V.I.S.) that can respond on demand to voice, text, and your laptops screen. It was highly technical, including a lockless ring buffer, FSM (finite state machine), and concurrency via asynchronous channels. All in rust! I will attempt to show you from first principles how this complexity arises.
Unlike related projects, you don’t have to click a button to get a response. In other words, it can interject when it sees fit.
Here’s a quick demo I posted on twitter. (pardon the provocative language, it tends to do better on twitter!)
first principles -> working application
We can send real-time(ish) video and audio to Gemini 2.0 flash and get a response, but we are still in charge of asking it when to respond.
Imagine a ChatGPT prompt that never ends. Audio and video are constantly being added to it. Our core challenge is deciding when to hit ‘Enter’ on the user’s behalf, breaking up the firehose of data into prompts, or conversation turns. How does it know when to interject?
We now run into the first problem.
problem one: semantically segmenting input (figuring out which segments of input the model has to respond to)
In other words, when do we ask the LLM (a generative model), when to generate. Do we need a different model to tell the other model when to fire? It’s actually much easier than that.
What we do is we flip the problem on its head, instead of figuring out when to generate, we ask it to figure out when to stay silent. In other words, We give the model the opportunity to stay silent on input (ie a tool/system instruction). What this does is essentially allow the model to generate a word that we know to ignore and consider silence. It’s still technically generating but it’s more of an ACK than a true response.
This still comes at some cost, it’s not like we can do this every 20ms. So now we come to problem 2.
problem two: how often can we ask the model to generate?
For video this is easy, record at X FPS (I choose 2 fps, FRAME_INTERVAL=500ms) and every Y frames (I set FRAMES_PER_BATCH=2, so every second) ask the model to either choose silence or respond. We also loosely hash each frame and compare to make sure the frames we send aren’t close to the same to save on bandwidth.
For audio this is significantly harder. We choose to sample audio at 20ms, so asking the model for a response every period, is much too demanding. The Gemini API has built in VAD (voice activity detection). This is how Discord (or Zoom) only streams audio when you speak instead of truly being always on. It’s the thing which tells your Discord circle when it can be green. When it detects that you have stopped talking it sends a response, essentially the default behaviour is that it will wait until your system audio and mic are completly silent before responding.
If 2 people are talking over each other, or in conversation, we need to respond even when the VAD is activated. Even while there is constant speech. Or even, if someone was speaking fast, and we wanted to comment on a sentence in the middle of their speech instead of waiting for them to stop talking, we need a different approach. Now we have problem 3.
(sub-)problem three: semantic VAD (how do we figure out the minimum viable segment to ask for a response to?)
The first thing we do is explicitly disable the built in VAD in the Gemini API because it is enabled by default (using realtimeInputConfig.automaticActivityDetection.disabled). Then we run (our own) VAD and ASR (realtime transcription/captions) in parallel, (in my design we actually run 2 different ASRs on separate threads incase one is busy, might be overkill).
When the VAD activates (noise/speech initially detected) we start streaming the audio in 20ms chunks. Simultaneously, we start the ASR on the speech, (ie we start transcribing). The ASR can be a bit slow which is why we use the VAD in parallel instead of just waiting for words to be transcribed. Once either the VAD closes (it detects silence) OR the ASR transcribes a full sentence, we ask Gemini to respond. We never send the transcribed sentence as text, we just mark where in the audio stream Gemini should respond, it can ingest audio natively.
handling speech + video simultaneously (VAD/ASR open) and video only (VAD/ASR closed)
When speech starts (VAD opens), we continue streaming video at 2fps, but we handover deciding when to respond to the VAD/ASR instead of doing it every 2 frames. Also when there is just video, we set the Gemini API to NO_INTERRUPTION, which basically queues the video turns on the gemini side so we get a response to every frame, even if we have to wait some marginal latency. If you don’t set NO_INTERRUPTION, each subsequent turn will cancel your previous generation if it hasn’t finished yet.
When audio starts we switch to “START_OF_ACTIVITY_INTERRUPTS”, which basically means when we start streaming audio, we cancel any pending video turns, so it can respond to the user faster. To make sure it responds to up to date info on the screen, we also force send a frame right after we stop streaming audio but before we ask for a response.
Essentially, we place more importance on maybe responding to voice than responding to video.
Note that the gemini API uses activity_start/activity_end messages to demarcate “turns”. Essentially, when we “ask for a response” what actually needs to happen is that we need to send an activity_end. And for an activity_end to be sent it needs to be preceded by an activity_start. When I say “start streaming audio” I mean send an activity_start and then start streaming. When I saw “ask for response” I mean send an activity_end.
this is how we implement it in code:
The key issue is we have to do this segmentation in real-time while we are already streaming data to the API. We are building the railroad as the train is chugging along the tracks. I’ll first explain how I implemented it and then tell the rationale in the next section.
1. Three-Layer Architecture
The system is organized into three distinct layers that communicate via channels:
// Layer 1: Media Capture (audio + video)
let (media_tx, _) = broadcast::channel::<MediaEvent>(256);
// Layer 2: Turn FSM (manages turn boundaries)
let (outgoing_tx, outgoing_rx) = mpsc::unbounded_channel::<Outgoing>();
// Layer 3: Gemini WebSocket I/O
let (ws_out_tx, ws_out_rx) = mpsc::unbounded_channel::<WsOutbound>();
let (ws_in_tx, ws_in_rx) = mpsc::unbounded_channel::<WsInbound>();
2. Audio Segmentation with VAD + ASR
The AudioSegmenter runs in a dedicated thread and implements the dual VAD/ASR approach:
// VAD detects speech immediately (80ms threshold)
if self.voiced_score >= 3.0 { // ~60ms of speech
self.state = BoundaryState::Recording;
// Start streaming audio immediately
self.send_activity_start();
}
// ASR runs in parallel on worker threads
if timestamp.duration_since(self.last_asr_poll).as_millis() >= 400 {
self.poll_asr(); // Submit audio to ASR workers
}
// Close segment when either:
// 1. VAD detects 500ms of silence
if silence_ms >= 500 {
self.send_activity_end();
}
// 2. ASR detects a complete clause
if self.is_valid_clause(&proposal.text) {
self.send_activity_end();
}
3. Simple Turn FSM
The FSM manages the interaction between audio and video, implementing the NO_INTERRUPTION and START_OF_ACTIVITY_INTERRUPTS modes (diagram included):
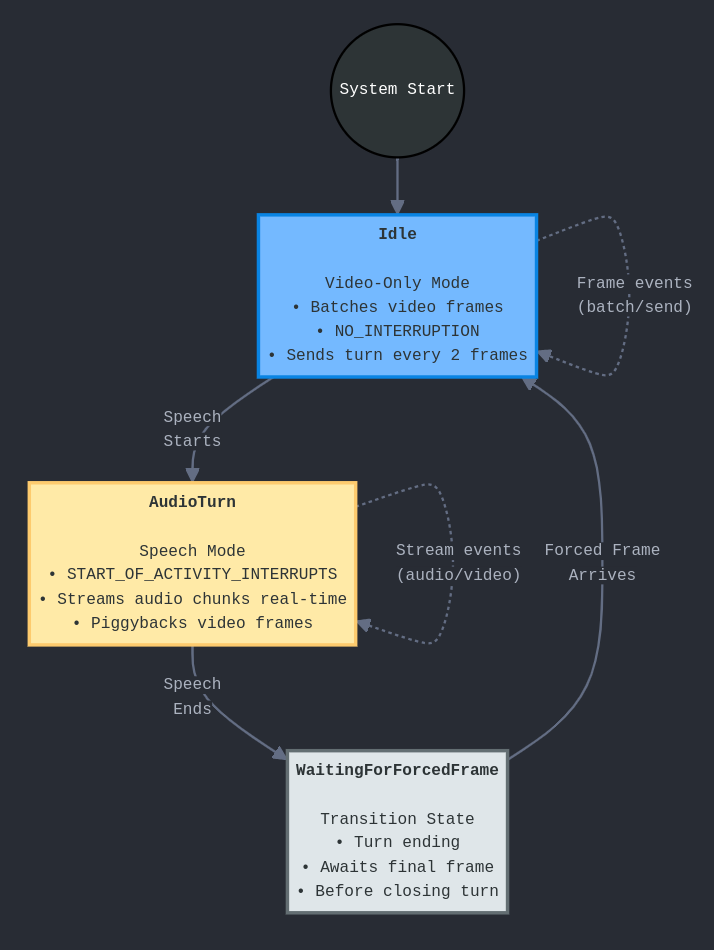
match (&self.state, event) {
// Video-only mode: batch frames
(State::Idle, Event::Frame { jpeg, hash }) => {
self.frame_batch.push(jpeg);
if self.frame_batch.len() >= FRAMES_PER_TURN {
// Send batch with NO_INTERRUPTION (default)
self.send_activity_start();
for frame in &frames {
self.send_video(frame);
}
self.send_activity_end();
}
}
// Audio starts: switch to interrupt mode
(State::FrameBatch, Event::SpeechStart) => {
// Cancel pending video generations
self.send_activity_handling_update("START_OF_ACTIVITY_INTERRUPTS");
self.send_activity_start();
self.state = State::AudioTurn;
}
// Stream audio in real-time
(State::AudioTurn, Event::AudioChunk(pcm)) => {
self.send_audio(&pcm);
}
// Piggyback video frames during audio
(State::AudioTurn, Event::Frame { jpeg, hash }) => {
self.send_video(&jpeg);
}
// Speech ends: force capture fresh frame
(State::AudioTurn, Event::SpeechEnd) => {
// Request forced frame capture
self.media_tx.send(MediaEvent::ForceCaptureRequest);
self.state = State::WaitingForForcedFrame;
}
// Send forced frame and reset to NO_INTERRUPTION
(State::WaitingForForcedFrame, Event::Frame { jpeg, hash }) => {
self.send_video(&jpeg);
self.send_activity_handling_update("NO_INTERRUPTION");
self.send_activity_end();
self.state = State::Idle;
}
}
4. WebSocket Protocol Implementation
The system carefully separates activity markers from data to comply with Gemini’s API requirements:
// Activity markers sent separately
fn send_activity_start(&mut self) {
let msg = json!({ "activityStart": {} });
self.outbound.push(WsOutbound::Json(msg));
}
// Audio/video data sent without flags
fn send_audio(&mut self, pcm: &[u8]) {
let msg = json!({
"audio": {
"data": base64::encode(pcm),
"mimeType": "audio/pcm;rate=16000"
}
});
self.outbound.push(WsOutbound::Json(msg));
}
// Mode switching for interruption handling
fn send_activity_handling_update(&mut self, mode: &str) {
let msg = json!({
"setup": {
"realtimeInputConfig": {
"activityHandling": mode
}
}
});
self.outbound.push(WsOutbound::Json(msg));
}
5. Key Implementation Details
- 20ms audio chunks: Audio is captured and streamed in 20ms chunks (320 samples at 16kHz).
- Ring buffer: A lock-free ring buffer stores 20 seconds of audio for ASR processing.
- Forced frame capture: When audio ends, we force capture a fresh video frame to ensure Gemini sees the latest screen state because we may have canceled buffered video frames.
- Latency tracking: The FSM tracks turn end times and calculates response latencies. You can use this to further tune timings and adapt to newer/faster models.
- Deduplication: Video frames are hashed to avoid sending duplicates.
- Non-blocking: the bulk of the implementation complications also come from the fact I was running into issues of things blocking and sort of over-engineered it.
concurrency design decisions
We use the three layers so instead of passing callbacks into callbacks or having all threads fight over a central Arc<Mutex
The reason for the dedicated VAD/ASR threads are easy: If you run asr_model.transcribe(audio_chunk) on your main async runtime, the entire application will freeze for the duration of the call, missing video frames and failing to respond to network events.
We use a broadcast::channel for media events, because raw media events (a new video frame, an audio chunk) are the “source of truth” and might be propagated down to many consumers.
The ring buffer is a natural choice for audio, and needed to be lockless as to not block on the downstream slower ASR processing thread. It needs to run every 20ms.
We use an mpsc::unbounded_channel for outgoing commands because there is only one consumer for these commands: the WebSocket task. Using an unbounded channel means the FSM’s send() call will never block. It can queue up commands as fast as it wants. The trade-off is that if the network is very slow, this queue could grow and consume a lot of memory. My network is fast, but this is a shaky design decision, if I were spending more time I would consider more carefully where I want backpressure in the system.
Also I am not sure if this is the most “Rust-y” idiomatic way to do this. This is just how I reasoned about it.
issues
I unfortunately am far too busy to maintain or take this project any further.
- It currently only works on Linux and Xorg. Also only tested with DWM, no other window manager.
- It is super janky, I think the prompting could use a lot of work, it needs to stay silent more I think.
- The ASR is poorly tuned (tested only in silent room) and unoptimized for speed.
- Codebase is messy
Instead of spending time fixing it to be usable, (which would likely require switching to tauri along with a bunch of other big changes), I leave this write up as a general guide to anyone going along this path. I think this would be considered the “hard part”, it took like 3-5 architectural iterations and figuring out what the Gemini API does.
source code
Here is the code, it’s decent but not perfect. This write up is probably more valuable. The most salvageable thing might be my low level, websockets based, Gemini API client.
I did this in relatively little time (<2 weeks, ~25 hours).